В какой-то момент развития Indigo — кроссплатформенной C++ библиотеки для решения задач химической информатики — мы осознали, что любая нормальная библиотека такого рода должна позволять third-party расширения. Сказано-сделано. Indigo обрела поддержку плагинов. Обёртки на Java, Python и C# также расширяемы, при этом плагин на соответствующем языке является обёрткой бинарного модуля-плагина на C++. Всё это работает на Windows, Linux и Mac OS X. Дальше речь пойдёт о проблемах, с которыми мы столкнулись при линковке бинарных модулей, и о том как эти проблемы решить.
Постановка задачи
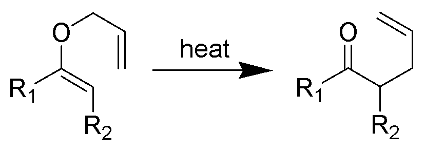
Есть библиотека на C++, назовём её «Core». В ней есть какое-то количество классов и некоторый интерфейс на C, который используется для «оборачивания» библиотеки в Java/Python/C# модули.
Есть ещё одна библиотека на C++, назовём её «Plugin». В ней тоже есть классы и
Core линкуется в динамическую библиотеку, назовём её libcore. Plugin тоже линкуется в динамическую библиотеку, назовём её libplugin. Эта библиотека не содержит в себе libcore.
Задача 1: libcore должна загружаться в адресное пространство программы на Java/Python/C# при инициализации соответствующей обёртки Core. Тип операционной системы (Windows/Linux/Mac OS X) и «битность» (32/64) должны определяться автоматически, т.е. нужно выбрать из коллекции сборок libcore для всех платформ правильную, и загрузить именно её. Сразу оговоримся, что обёртки поставляются в комплекте со всеми вариантами библиотеки, чтобы таким образом не нарушать «переносимость» и не причинять головную боль разработчикам, которые будут использовать обёртку.
Задача 2: libplugin должен загружаться в адресное пространство программы на Java/Python/C# при инициализации соответствующей обёртки Plugin. Само собой, и в этом случае ОС и битность определяются автоматически. Кроме того, libplugin должна «увидеть» уже загруженную libcore и подцепить из неё нужные C++ классы и глобальные функции.
Решение задачи 1
В Linux и gcc помогут ключи -m32 и -m64, с которыми собирается соответственно
В Windows и Visual Studio дело делается установкой платформы Win32 или x64 в свойствах проекта. Чтобы платформа 64 появилась на
На Mac OS X «битность» не является проблемой благодаря технологии универсальных бинарников. Не иначе как для компенсации этого удобства, бинарники, собранные для версии Mac OS X 10.6, не запускаются на 10.5, так что имеет смысл собирать для 10.5 и 10.6 отдельно. Или собирать только для 10.5 и рассчитывать, что они подойдут для 10.6, но мы это не пробовали.
Теперь пара слов о том, как определить платформу на этапе выполнения программы на Java/Python/C# и загрузить нужный модуль libcore.
Java
Узнать тип операционной системы можно с помощью System.getProperty("os.name"). «Битность», соответственно, через System.getProperty("os.arch"). Версия Mac OS X находится в System.getProperty("os.version").
После того, как платформа определена и путь к подходящему бинарнику libcore получен, загрузить бинарник можно вызовом System.load.
Python
Константа os.name равна "nt", если дело происходит на Windows, и "posix", если это Linux или Mac OS X. Последняя отличается тем, что platform.mac_ver() возвращает определённую структуру данных, из которой как раз можно узнать версию системы. Битность можно узнать с помощью platform.architecture()
Загрузку бинарного модуля в Python, как и дальнейшую работу с ним, проще всего осуществлять с помощью ctypes.
C#
Операционная система в данном случае однозначно Windows. (Нет, до Mono мы ещё не добрались.) Битность можно определить, например, проверкой IntPtr.Size. Для вызова
Решение задачи 2
Функции, а также методы C++ классов, которые то же самое что функции, в терминологии линковщика называются символами. Символы, которые библиотека «показывает» наружу, называются экспортируемыми символами. Символы, которые библиотека берёт из других библиотек, называются импортируемыми символами. Надо сделать так, чтобы символы libcore, которые используются в libplugin, экспортировались из libcore и импортировались в libplugin. В каждой ОС динамический линковщик работает по-своему, и рецепты соответственно для каждой ОС свои.
Linux
С экспортом и импортом принципиальных сложностей нет. линковщик (ld), который собирает объектные файлы в .so-модуль, все неопределённые (undefined) в библиотеке глобальные символы считает импортируемыми, а все определённые символы считает экспортируемыми (есть возможность экспортировать только избранные символы, но нам это не нужно). Динамический линковщик (который не ld, а часть операционной системы) при загрузке libcore запишет все экспортированные из неё символы, а при загрузке libplugin обнаружит в ней символы, ждущие импорта, и импортирует их в libplugin из libcore.
Есть ещё одна особенность. Символы могут быть помечены импортируемыми «откуда угодно», или импортируемыми из конкретной библиотеки.
Импорт символов из конкретной библиотеки
ld помечает символ импортируемым из конкретной библиотеки если при линковке указать .so-файл, из которого этот самый символ экспортируется. То есть, в libplugin.so будет чётко прописано, что такой-то символ импортируется из библиотеки libcore.so и только из неё. Кроме того, динамический линковщик будет пытаться при загрузке libplugin.so загрузить libcore.so из директорий, записанных в:
- Переменной окружения LD_LIBRARY_PATH. При этом, учитывается только значение этой переменной на этапе запуска программы. Фокусы с подменой LD_LIBRARY_PATH по ходу пьесы не работают. Для программ с setuid/setgid LD_LIBRARY_PATH и вовсе игнорируется.
- Кэше /etc/ld.so.cache
- /lib
- /usr/lib
Если libcore.so не будет найдена ни в одной из указанных директорий, то загрузка libplugin.so не пройдёт успешно. Нетрудно понять, что для наших целей такой подход не годится, т.к. libcore мы распространяем в двух вариантах (32 и 64 бита) и обязательно вместе с самой программой, чтобы разработчики на Java и Python не терпели неудобств с непереносимостью своих программ из-за бинарных модулей.
Импорт символов из любой библиотеки
Если в ld при линковке libplugin.so не передавать libcore.so, то он пометит отсутвующие символы как импортируемые, но не укажет откуда именно. Динамический линковщик затем при загрузке libplugin.so не станет пытаться загрузить libcore.so, а попытается найти отсутствующий символ среди всех загруженных на данный момент библиотек (+в самой программе). Конечно, libcore.so будет среди них, т.к. мы инициализировали Core до того, как начали инициализацию Plugin. Всё очень хорошо, но есть ещё одна деталь.
На самом деле, ld перебирает не все загруженные на данный момент библиотеки, а только те из них, которые были загружены с флагом RTLD_GLOBAL (man dlopen). Те библиотеки, которые загружены с флагом RTLD_LOCAL, подходят только для импорта символов конкретно из них (см. предыдущий заголовок). Виртуальная машина Java и её System.load(), что бы вы думали, конечно загружает все библиотеки с RTLD_LOCAL, без вариантов. Но есть обходной путь! Он появился в glibc 2.2 (2000 г.) не иначе как специально для Java: это флаг RTLD_NOLOAD. После вызова System.load("/path/to/libcore.so") можно вызвать (уже не из Java, а из C):
dlopen("/path/to/libcore.so", RTLD_NOLOAD | RTLD_GLOBAL);
и символы из libcore.so, ранее «закреплённые» за libcore.so, станут доступны для импорта по схеме «откуда угодно». Динамический линковщик отдаст их в нужный момент в libplugin. Дополнительная изюминка заключается в том, что вызов dlopen для libcore.so с RTLD_NOLOAD можно оформить в самой libcore.so, в какой-нибудь функции инициализации. Будет работать.
Что касается загрузки .so-файлов в Python, то с ним всё гораздо проще, т.к. ctypes поддерживает произвольные флаги для загрузки библиотек, в т.ч. и RTLD_GLOBAL:
lib = CDLL("/path/to/libcore.so", mode=RTLD_GLOBAL);
Mac OS X
Правила линковки на Mac OS X такие же, как и в линуксе, есть только небольшие различия в терминологии и опциях линковщика. Схема с привязкой символов к библиотеке, описанная в предыдущем разделе, здесь имеет название: two-level namespace (man ld). Альтернативная схема, которая нам и нужна, называется flat namespace. На этапе компиляции libplugin надо выбрать, по какой схеме испортировать в неё символы. Для нас это означает, что надо передать в ld ключ "-flat_namespace".
Использование flat namespace, по замыслу разработчиков, не отменяет необходимости задания в командной строке ld всех зависимых .dylib-файлов (т.е. в нашем случае libcore.dylib). Это странно, но оправдано для более сложных случаев с косвенными зависимостями (indirect dynamic libraries), которые к нашей задаче не имеют отношения. Можно, тем не менее, попросить ld закрыть глаза на неразрешённые зависимости, передав ему ключ "-undefined suppress". В этом случае динамический линковщик будет разрешать их в рантайме, как в Linux.
Трюк с RTLD_NOLOAD | RTLD_GLOBAL в Mac OS X тоже актуален.
Windows
В Windows нет динамического линковщика.
Его там не может быть в принципе из-за отсутствия поддержки position-independent code, но от этого не легче. В Windows есть только загрузчик динамических библиотек (loader), который, мягко говоря, не совсем в курсе про динамическое связывание. Вся работа по динамическому связыванию делается самой загружаемой DLL на этапе инициализации. Компилятор и линковщик (link.exe) должны позаботиться о том, чтобы DLL сделала эту работу правильно. Программист, в свою очередь, должен позаботиться о том, чтобы компилятор и линковщик правильно поняли свою задачу.
Экспортируемые и импортируемые символы
По указанным выше причинам, в DLL не может быть неопределённых (undefined) символов. Никто не проверит на этапе загрузки DLL, какие символы в ней «defined», а какие «undefined». Такого вопроса просто не стоит. Все символы должны быть определены. В том числе и символы, которые импортируются из другой DLL.
Этот парадокс разрешается следующим образом: при компиляции модулей DLL, в которую импортируются символы (в нашем случае plugin.dll) компилятор на месте импортируемых символов создаёт функцию-"прослойку", которая
- Загружает в память DLL, в которой находится нужная функция (LoadLibrary("core.dll")). Большая удача, нет мороки с путями. Есди загрузить core.dll из нужной директори заранее (LoadLibrary("\path\to\core.dll")), то plugin.dll не станет искать core.dll в системных директориях, а просто «подхватит» уже загруженную копию.
- Получив указатель (handle) на загруженную DLL, ищет в ней нужную функцию (GetProcAddress) и вызывает её с теми параметрами, которые были переданы в неё саму, т.е. в прослойку.
link.exe не догадается сделать такую прослойку для всех C++ функций, которые не определёны в DLL (хотя догадается сделать это для
Более того, link.exe не догадается экспортировать из DLL символы, которые в ней определены. Перед каждой функцией, которую вы хотите экспортировать из core.dll, надо писать __declspec(dllexport). Это касается и C, и C++ функций. При линковке любой DLL помимо собственно DLL возникает маленький файл с расширением .lib — он и содержит вышеуказанные «прослойки» для всех экспортированных функций.
Получается, что одни и те же C++ функции должны объявляться в Core как __declspec(dllexport), а в Plugin — как __declspec(dllimport). Объявляются эти функции в заголовочных файлах, которые одинаково включаются в Core и в Plugin. Самое время воспользоваться препроцессором:
#ifdef _WIN32 #ifdef PLUGIN #define DLLEXPORT __declspec(dllimport) #else #define DLLEXPORT __declspec(dllexport) #endif #else #define DLLEXPORT #endifи перед всеми функциями Core, которые нужны в Plugin, писать макрос DLLEXPORT. При сборке plugin.dll надо указать компилятору макрос PLUGIN.
Экспортирование C++ классов
Физически, C++ класс в скомпилированных модулях — это набор его методов, т.е. функций. Экспортирование класса означает экспортирование всех его методов, кроме приватных. Экспорт и импорт классов осуществляется тем же образом, что экспорт и импорт функций. Можно использовать тот же макрос DLLEXPORT, что и для функций.
Написав DLLEXPORT класса, у которого есть суперкласс, или неприватные поля — объекты каких-либо классов, или неприватные методы, возвращающие объекты каких-либо классов, то при компиляции вы заметите следующий варнинг:
warning C4251: *** : class *** needs to have dll-interface to be used by clients of class ***Это, в принципе, правильное предупреждение. Если Plugin импортирует класс «CoreClass», определённый в Core, то он конечно будет использовать его публичные (public) методы и публичные поля. Или отнаследуется и будет использовать защищённые (protected) методы и поля. Все классы, возникающие в процессе работы с CoreClass, должны быть доступны через импорт так же, как и сам CoreClass. И всех их надо тоже пометить как DLLEXPORT, о том и речь в варнинге C4251. Иначе Plugin ждёт ошибка линковки.
Если бы в проектах Core и Plugin не было бы классов-шаблонов, то на этом бы наше повествование благополучно закончилось. Но шаблоны у нас есть. Нет, сами классы, которые надо экспортировать, не являются шаблонами, но среди их методов есть такие, которые принимают или возвращают объекты шаблонных классов. Вот на тему этих шаблонных классов и возникает C4251.
Можно, конечно, попытаться писать DLLEXPORT при объявлении шаблонов. В простых случаях это даже будет работать. Но на самом деле это лишено всякой логики. Шаблон — это не класс, он никогда не экспортируется. Экспортируется конкретный класс, который создаётся в тот момент, когда компилятор встречает инстанцированный шаблон. Выйдет так, что все классы-экземпляры «экспортируемого» шаблона будут экспортироваться из Core и импортироваться в Plugin. Это хорошо до тех пор, пока Plugin не воспользуется одним из шаблонов Core с параметром, которого нет в Core. (То есть, из Core попросту не экспортируется данный экземпляр шаблона). И даже тогда всё может быть в порядке; но рано или поздно окажется, что компилятор не в состоянии понять, что не надо импортировать данный экземпляр шаблона из Core, а надо его создать. В нашем случае это произошло, когда один «экспортированный» шаблон с неэкспортированным экземпляром инстанцировался в другом, тоже с неэкспортированным экземпляром. Дело закончилось ошибкой видаerror LNK2001: unresolved external symbol "__declspec(dllimport) ..."
Есть ещё один способ обойти C4251, под названием «explicit template instantiation», т.е. явное экспортирование экземпляра шаблона. Он подробно разбирается в этой статье, в применении к STL, с которой кстати приписать DLLEXPORT к объявлению шаблона нет возможности. Код получается немыслимо громоздким, а результаты — неутешительными. В статье отмечен тот факт, что экспортирование шаблонных классов в случае линковки нескольких (независимых друг от друга) DLL, содержащих одни и те же шаблонные классы, приведёт к ошибкам линковки вида
LNK1169: one or more multiply defined symbols foundДа, link.exe, в отличие своего коллеги ld, не умеет определять и отбрасывать дубликаты функций в разных библиотеках.
Короче говоря, экспортировать шаблоны нет смысла и вообще нельзя. Есть два выхода из ситуации с C4251:
- Игнорировать, благо это варнинг, а не ошибка. core.dll и plugin.dll просто будут иметь по пачке одинаковых методов для шаблонных классов. Конфликта при загрузке не будет, поскольку классы не экспортированы. Ошибки линковки тоже не будет, если все не-шаблонные классы имеют в своём заголовке DLLEXPORT.
- Не экспортировать свои классы, а экспортировать только их методы, с помощью того же DLLEXPORT в объявлении каждого метода. Как ни странно, варнинг при этом исчезает. Странно, потому что опасность-то остаётся. Опасность заключается в том, что core.dll и plugin.dll всё равно будут иметь независимые реализации одних и тех же шаблонных классов; и если окажется так, что plugin.dll была собрана с иной версией этих классов, бинарно несовместимой с той, с которой была собрана core.dll, то они не смогут вместе работать с этими классами. В статье по ссылке выше сказано, что именно это может произойти с классами STL, когда одна библиотека собрана под VS7, а другая под VS8.
Прочие проблемы с Windows
Ещё пара неприятностей, по числу которых Windows и так лидирует с большим отрывом:
- Чтобы собрать plugin.dll, надо поставить в проекте Plugin зависимость на проект Core. Однако, если появилась необходимость завести в проектах Plugin и Core конфигурации сборки «Static», и собирать их в plugin-static.lib и core-static.lib, то зависимость останется, и её не убрать. core-static.lib будет вкомпиливаться в plugin-static.lib, вместе со своими глобальными переменными. Проект, который зависит от обеих библиотке Core и Plugin, при сборке обретёт две копии Core, и работать скорее всего не будет из-за наличия двух копий глобальных данных. Придётся создавать отдельные проекты CoreStatic и PluginStatic. Даже тогда, не получится оставить Core и Plugin пустыми и просто поставить им зависимости соответственно от CoreStatic и PluginStatic: при линковке Core и Plugin не будут экспортироваться символы. Придётся дублировать в Core/Plugin и CoreStatic/PluginStatic одинаковые наборы файлов.
- В компиляторе VS есть опция /MT, что означает, что рантайм (CRT) будет «вкомпилен» в библиотеку или программу. Это очень удобно, с учётом того что даже в самые современные версии Windows эта CRT не включена! В Windows есть только очень старая версия, а VS линкует с новой, которая доступна для Windows либо в составе VS, либо в виде отдельного пакета. Так вот, опция /MT в случае двух связанных между собой DLL приведёт к ошибке во времени выполнения. Она неизбежно случится, когда например память выделена в одной DLL, а освобождается (или даже копируется) другой DLL. Остаётся использовать опцию /MD и обеспечивать затем присутствие «Redistributable Package» на машине пользователя.