А оказывается, многие известные люди считают, что динамическое связывание это дурь и блажь. Серьёзное приложение-де не может находиться в зависимости от каких-то там обновляемых системных библиотек. В самом деле, от несанкционированных обновлений может быть не только польза (баг поправят, или там дыру закроют), но и серьёзный вред. При этом, оказывается, исправление бага в системной либе может быть полезно для одних приложений и вредно для других. Получается, и обновлять нельзя, и не обновлять нельзя.
Про поломку бинарной совместимости и говорить нечего, см. DLL Hell. Версионирование библиотек, придуманное для решения этой проблемы, по большому счёту только усугубляет её.
Короче, серьёзные приложения все свои библиотеки носят с собой, и в итоге ни память не экономится, ни место на диске, и сама идея динамически связываемых библиотек превращается в профанацию.
Статическое связывание, напротив, всё упрощает! Из-за отсутствия необходимости в PIC код становится много компактнее (что в большей части случаев перевешивает расходы на дублирование кода в приложениях), межмодульные оптимизации становятся возможны, плюс к тому экономятся драгоценные TLB. При этом ещё не надо забывать о том, что код нескольких копий одного процесса тоже является общим (равно как и код форкнутого процесса с родительским), то есть экономия памяти тоже не очень-то страдает.
Ещё одна причина, по которой используют динамически связываемые библиотеки — это разного рода плагины. Но для механизма плагинов этого динамическое связывание не является необходимостью. Достаточно динамической загрузки кода. Кстати, Windows DLL это как раз и есть динамически загружаемые, а не связываемые, библиотеки. Динамического связывания в Windows вообще нет. Код DLL не является position-independent.
Тут бы и подумать, что Windows со своими DLL идёт впереди прогресса, не поддаваясь на провокации. Но нет. Во-первых, само присутствие DLL как отдельных системных файлов порождает проблемы, о которых сказано в первых четырёх абзацах. Почему-то принято завязываться на DLL, а не линковать всё статически. Почему? Неизвестно.
Во-вторых, в Windows очень капризная libc. Она не переносит, когда память, выделенная в одном экземпляре, освобождается в другом! Из личного опыта скажу, что даже strcpy-ровать её нельзя, хотя по ссылке этого не написано. Что делает статическую линковку с libc бессмысленной в том случае, когда у вам есть более-менее сложные плагины. Приложения и их плагины должны линковаться с динамической libc. И вообще, в Windows море проблем с написанием плагинов.
Говорят (по самой первой ссылке) что в plan9 статическая линковка и всё при этом просто и удобно, в том числе с плагинами. Хотя и плагины там не очень нужны, при наличии 9P. Сам не пробовал, подтвердить не могу.
пятница, 9 декабря 2011 г.
пятница, 2 декабря 2011 г.
четверг, 3 ноября 2011 г.
Разработка языка программирования на Racket
Racket — современная платформа для разработки языков программирования, одна из самых прогрессивных, наследница Lisp.
Пара слов о Лиспе: будучи созданным 50 лет назад, он живёт и развивается до сих пор, причём последние 20 лет практически без финансирования. Что означает, что язык действительно хорош. Надо отметить, что Джон Маккарти (автор термина «искусственный интеллект», AI) изобрёл Лисп как подручное средство для создания этого самого AI. Маккарти умер, AI как не было так и нет, но идеи, заложенные в Лисп, в течение полувека находят применение в совершенно не связанных с AI областях. Что означает, что идеи действительно хороши.
Цель авторов Racket можно сформулировать так: дать разработчикам возможность создавать свои языки, не лишая их при этом прелестей Лиспа. «Лисп как основа и любой ваш каприз вдобавок» — звучит как предложение, от которого невозможно отказаться. В отличие от Common Lisp, где новые языки как правило создаются на базе грамматики S-выражений, в Racket для них допустима любая грамматика. Плюс к тому, отладчик и редактор с подсветкой синтаксиса — практически даром. Решительно невозможно отказаться.
По какой-то причине в сети нет подробного руководства по созданию своего языка в Racket «от и до». Впрочем, уже есть, раз вы его читаете. Оно было собрано по кускам из одного короткого примера, документации Racket и кода встроенных в Racket языков (Algol, Datalog). Для руководства такие изыски ни к чему, поэтому мы сейчас сделаем в Racket калькулятор. Типа такого:
Вещи, относящиеся к языкам, Racket желает видеть в одной из своих «системных» директорий, поэтому директорию, в которой мы ведём разработку (назовём её
Этап 1: базовый комплект
Начнём с лексического анализатора, который будет в файле
Настало время встроить наш анализатор в среду Racket. Это очень просто: нужно создать файл
Racket, увидев
 и видим сообщение «Parser error» из нашего
и видим сообщение «Parser error» из нашего
 Парсер успешно отработал и выдал в качестве результата набор конструкций вида
Парсер успешно отработал и выдал в качестве результата набор конструкций вида
 Запустив Macro stepper снова и выключив в нём опцию «macro hiding», мы можем наблюдать, во что в конечном итоге раскрылся наш код:
Запустив Macro stepper снова и выключив в нём опцию «macro hiding», мы можем наблюдать, во что в конечном итоге раскрылся наш код:

На этом этапе можно считать, что у нас есть парсер и компилятор. Всё это занимает 110 строк, не считая пустых строк и комментариев.
Этап 2: необходимые примочки
Если мы сейчас попробуем запустить отладчик (Debug) и поставить брекпоинт в код программы, нас ждёт неудача. Объясняется это просто: парсер в

Racket позволяет отладчику заходить в реализацию вашего языка в лисповых функциях, если в момент отладки модули с этими функциями открыты. Но нашего
Обратим теперь внимание на то, что для языка calc не работает REPL! Об этом честно собщается после выполнения программы (Run) чёрным текстом на жёлтом фоне. REPL не работает потому, что в реализации (

Благодаря умной работе механизма модулей, два и более открытых одновременно окна с программами на calc не конфликтуют и не засоряют окружение друг друга:

Самое время заметить, что ошибки с необъявленными переменными возникают на этапе выполнения программы, тогда как во всех нормальных средах они должны отлавливаться на этапе компиляции. Полноценный компилятор мы писать не будем, ограничимся проверкой того, что все используемые переменные встретились перед использованием в левой части. Файл

Попросим REPL делать то же самое (

Отметим, что ошибки времени выполнения всё же случаются, и снабжены бектрейсом:
На данный момент у нас есть всё необходимое, а написали мы всего 208 строк кода.
Этап 3: элементы роскоши
Такая беда: REPL не позволяет переводить строку. Нажатие Enter ведёт к немедленному отправлению строки на синтаксический анализ. Мы собирались дописать команду на следующей строке, но REPL безжалостен.
 Хорошая новость: поведение REPL можно настроить. Открываем снова
Хорошая новость: поведение REPL можно настроить. Открываем снова

Почти всё. Осталось только добавить подсветку синтаксиса. Ну и, например, комментарии, чтобы было что подсвечивать. Пусть комментарии будут в стиле bash — от символа «#» до конца строки. Обновляем
Информация о подсветке синтаксиса задаётся определённым образом в директиве
Внимание: чтобы подсветка синтаксиса заработала, надо перезапустить Racket! Если вдуматься, это значит, что при выполнении всех предыдущих операций Racket не надо было перезапускать! И даже test.calc можно было не закрывать. При том, что мы там «резали по живому» во многих местах. Racket истинно динамическая платформа. Вот что получится после перезапуска:

Подсветка синтаксиса в действии. В REPL, правда, она не работает (то есть работает, но не наша, а стандартная), но не будем придираться к мелочам. Racket — прекрасная вещь. Всё вышеописанное мы сделали, написав 268 строк кода. То, что получилось, можно скачать здесь. Вообще-то можно ещё сделать так, чтобы язык calc включался без
Пара слов о Лиспе: будучи созданным 50 лет назад, он живёт и развивается до сих пор, причём последние 20 лет практически без финансирования. Что означает, что язык действительно хорош. Надо отметить, что Джон Маккарти (автор термина «искусственный интеллект», AI) изобрёл Лисп как подручное средство для создания этого самого AI. Маккарти умер, AI как не было так и нет, но идеи, заложенные в Лисп, в течение полувека находят применение в совершенно не связанных с AI областях. Что означает, что идеи действительно хороши.
Цель авторов Racket можно сформулировать так: дать разработчикам возможность создавать свои языки, не лишая их при этом прелестей Лиспа. «Лисп как основа и любой ваш каприз вдобавок» — звучит как предложение, от которого невозможно отказаться. В отличие от Common Lisp, где новые языки как правило создаются на базе грамматики S-выражений, в Racket для них допустима любая грамматика. Плюс к тому, отладчик и редактор с подсветкой синтаксиса — практически даром. Решительно невозможно отказаться.
По какой-то причине в сети нет подробного руководства по созданию своего языка в Racket «от и до». Впрочем, уже есть, раз вы его читаете. Оно было собрано по кускам из одного короткого примера, документации Racket и кода встроенных в Racket языков (Algol, Datalog). Для руководства такие изыски ни к чему, поэтому мы сейчас сделаем в Racket калькулятор. Типа такого:
X = 2.8 Y = (X + 1) * 5 print X / Yс блекдж... пардон, с пошаговым выполнением, бектрейсами и REPL.
Вещи, относящиеся к языкам, Racket желает видеть в одной из своих «системных» директорий, поэтому директорию, в которой мы ведём разработку (назовём её
work), лучше с самого начала внести в соответствующий список. В среде DrRacket это делается следующим образом: меню Language → Choose Language → кнопка «Show Details» → раздел «Collection Paths» → Add. В директории work у нас будет директория calc, где будут файлы, относящиеся к новому языку. Этап 1: базовый комплект
Начнём с лексического анализатора, который будет в файле
calc/lexer.rkt:#lang racket
(require
; lex -- стандартное средство для построения лексических анализаторов
parser-tools/lex
; Библиотека регулярных выражений для lex. Символы, импортированные из неё,
; будут предваряться знаком двоеточия, в целях избежания конфликтов имён
(prefix-in : parser-tools/lex-sre))
; Указанные вещи из этого модуля идут на экспорт
(provide value-tokens op-tokens
position-line position-col position-offset
calc-lexer)
; Регулярные выражения для букв, цифр и всяких пробелов
(define-lex-abbrevs
(lex:letter (:or (:/ #\a #\z) (:/ #\A #\Z)))
(lex:digit (:/ #\0 #\9))
(lex:whitespace (:or #\newline #\return #\tab #\space #\vtab)))
; Токены, имеющие значения -- идентификатор (например X) и число (например 2.8)
(define-tokens value-tokens (IDENTIFIER NUMBER))
; Токены, не имеющие значений -- арифметические операции, скобки, присваивание,
; операция печати (PRINT) и специальный токен EOF
(define-empty-tokens op-tokens
(EOF ASSIGN PLUS MINUS MULTIPLY DIVIDE LEFT-PAREN RIGHT-PAREN PRINT))
; calc-lexer -- это функция, полученная в результате вызова lexer-src-pos
(define calc-lexer
; lexer-src-pos отличается от lexer тем, что выдаёт не просто токены,
; а position-token -- токены с информацией об их положении в исходном файле
(lexer-src-pos
; пробелы и прочее пропускаем, рекурсивно запуская lexer дальше
((:+ lex:whitespace) (return-without-pos (calc-lexer input-port)))
; токены операций
("=" (token-ASSIGN))
("+" (token-PLUS))
("-" (token-MINUS))
("*" (token-MULTIPLY))
("/" (token-DIVIDE))
("(" (token-LEFT-PAREN))
(")" (token-RIGHT-PAREN))
("print" (token-PRINT))
; идентификатор = буква + [произвольный набор букв и цифр]
((:: lex:letter (:* (:or lex:letter lex:digit)))
(token-IDENTIFIER (string->symbol lexeme)))
; число = [знак] + не менее одной цифры + [точка [с цифрами]]
((:: (:? #\-) (:+ lex:digit) (:? (:: #\. (:* lex:digit))))
(token-NUMBER (string->number lexeme)))
; специальный токен EOF необходимо вернуть при достижении конца файла
((eof) 'EOF)))
Теперь парсер, calc/parser.rkt:#lang racket
(require
; модуль с генератором парсеров
parser-tools/yacc
; модуль, содержащий нужную нам функцию raise-read-error
syntax/readerr
; наш лексический анализатор
calc/lexer)
(provide calc-read-syntax
calc-read)
; Функция, которую мы будем вызывать при ошибке парсинга
(define (on-error source-name)
(lambda (tok-ok? tok-name tok-value start-pos end-pos)
; генерирует исключение
(raise-read-error
"Parser error" ; текст исключения
source-name ; имя файла
(position-line start-pos) ; номер строки с ошибкой
(position-col start-pos) ; номер колонки с ошибкой
(position-offset start-pos) ; смещение от начала файла
(- (position-offset end-pos) ; длина фрагмента с ошибкой
(position-offset start-pos)))))
; calc-parser -- это функция, возвращающая функцию, полученную
; в результате вызова функции parser из модуля parser-tools/yacc
(define (calc-parser source-name)
(parser
(src-po s) ; это нужно для того, чтобы в функцию обработки ошибки
; передавалась позиция проблемного куска
(start start) ; стартовый нетерминал у нас называется start
(end EOF) ; конец файла у нас называется EOF
(tokens value-tokens op-tokens) ; две группы токенов, определённые в calc-lexer
(error (on-error source-name)) ; функция обработки ошибок (см. выше)
; Грамматика
(grammar
; программа = команды
(start
((statements) $1))
(statements
; команды = ничто
(() '())
; или команда + команды
; $1 и $2 обозначают соответственно первый и второй элементы
; сопоставления, то есть statement и statements
((statement statements) (list* $1 $2)))
(statement
((assignment) $1)
((printing) $1))
(constant
((NUMBER) $1))
(expression
; выражение = терм
((term) $1)
; или выражение плюс/минус токен.
; PLUS и MINUS здесь -- терминалы, взятые из op-tokens из calc/lexer.
((expression PLUS term) (list 'plus $1 $3))
((expression MINUS term) (list 'minus $1 $3)))
(term
((factor) $1)
((term MULTIPLY factor) (list 'multiply $1 $3))
((term DIVIDE factor) (list 'divide $1 $3)))
(factor
((primary-expression) $1)
((MINUS primary-expression) (list 'negate $2))
((PLUS primary-expression) $2))
(primary-expression
((constant) $1)
((IDENTIFIER) (list 'value-of $1))
((LEFT-PAREN expression RIGHT-PAREN) $2))
(assignment
((IDENTIFIER ASSIGN expression) (list 'assign $1 $3)))
(printing
((PRINT expression) (list 'print $2))))))
Теперь свяжем лексический и синтаксический анализаторы в одно целое с помощью функции, которая принимает некоторый входной поток (в Racket это называется «порт») и соответствующее ему имя файла, и возвращает результат граматического разбора. Правим дальше calc/parser.rkt:(define (parse-calc-port port file)
; посчитать номера строк заранее
(port-count-lines! port)
; создать и сразу вызвать парсер
((calc-parser file)
; и передать в него функцию, которая должна выдавать токены один за другим
(lambda ()
; calc-lexer как раз это и делает
(calc-lexer port))))
Поскольку наш анализатор должен будет работать в среде Racket на тех же правах, на которых работает «родной» анализатор, мы должны реализовать функции calc-read и calc-read-syntax, которые придут на замену стандартным read и read-syntax. Окончание calc/parser.rkt:(define (calc-read in) (syntax->datum (calc-read-syntax #f in))) (define (calc-read-syntax source-name input-port) (parse-calc-port input-port source-name))Пояснение: в то время как
calc-read возвращает прочитанные данные (datum) вида ((assign X (+ 1 2)), calc-read-syntax возвращает синтаксические объекты, что есть по сути те же самые данные, но с привязкой к участкам исходного файла и прочей информацией. В зависимости от режима работы Racket пользуется либо read, либо read-syntax, и во избежание неожиданностей лучше сделать их одинаковыми. Что и сделано: calc-read просто берёт синтаксические объекты из calc-read-syntax и превращает их в данные с помощью syntax->datum.Настало время встроить наш анализатор в среду Racket. Это очень просто: нужно создать файл
calc/lang/reader.rkt следующего содержания:(module reader syntax/module-reader
#:language 'racket ; об этом позже
#:read calc-read ; переопределение стандартного read
#:read-syntax calc-read-syntax ; переопределение стандартного read-syntax
#:whole-body-readers? #t ; этот флаг устанавливается в том случае, когда наши
; read и read-syntax всегда читают входной поток до
; конца (calc-read и calc-read-syntax так и делают)
(require calc/parser)) ; модуль, в котором лежат calc-read и calc-read-syntax
Racket, увидев
#lang calc в начале файла, будет искать calc/lang/reader.rkt в системных директориях, включая work, где мы всё и делаем. Поэтому мы уже можем начинать писать код на calc в среде Racket. Создадим файл test.calc:#lang calc X = 3 Y = X + 1 Print X * X + Y * Y pi = 3.1415926535 r = 12.2 l = 40 Print pi * r * (2 + l)Запускать файл на выполнение ещё рано, т.к. реализации языка пока ещё нет. Но уже можно посмотреть на результат синтаксического анализа кода, для чего в Racket есть удобный инструмент под названием Macro stepper. Нажимаем...

calc/parser.rkt. Ошибка состоит в том, что слово Print написано с большой буквы, тогда как лексический анализатор допускает только «print» без вариантов. Сделаем его нечувствительным к регистру (calc/lexer.rkt):; вспомогательная функция, преобразующая строку в выражение, нечувствительное
; к регистру, например "foo" -> (:: (:or #\f #\F) (:or #\o #\O) (:or #\o #\O))
(define-for-syntax (string->ci-pattern s)
(cons ':: (map (lambda (c)
(list ':or (char-downcase c) (char-upcase c)))
(string->list s))))
; специализированный макрос для применения в лексическом анализаторе
(define-lex-trans lex-ci
(lambda (stx)
(syntax-case stx ()
((_ id) ; здесь id -- это строка, которую мы преобразуем, т.е. "print"
(with-syntax ((result (string->ci-pattern
(syntax->datum #'id))))
#'result)))))
(define calc-lexer
(lexer-src-pos
((:+ lex:whitespace) (return-without-pos (calc-lexer input-port)))
("=" (token-ASSIGN))
("+" (token-PLUS))
("-" (token-MINUS))
("*" (token-MULTIPLY))
("/" (token-DIVIDE))
("(" (token-LEFT-PAREN))
(")" (token-RIGHT-PAREN))
((lex-ci "print") (token-PRINT))
((:: lex:letter (:* (:or lex:letter lex:digit)))
(token-IDENTIFIER (string->symbol lexeme)))
((:: (:? #\-) (:+ lex:digit) (:? (:: #\. (:* lex:digit))))
(token-NUMBER (string->number lexeme)))
((eof) 'EOF)))
Запускаем Macro stepper вторично на test.calc и видим
(assign X 3) (assign Y (plus (value-of X) 1))Что не является валидным кодом на Racket, что подтверждается сообщением «unbound identifier in module». Но по замыслу — полученный код и не должет являться кодом на Racket! Для исполнения этого кода мы должны создать набор макросов, преобразующих его в код на Racket, а точнее — в синтаксические объекты. Декларация
#:language в calc/lang/reader.rkt — именно об этом. Мы написали #:language 'racket исключительно потому, что совсем ничего не писать система не позволяет. На самом деле, в этом месте нужно указать путь к модулю с макросами:(module reader syntax/module-reader #:language 'calc/language #:read calc-read #:read-syntax calc-read-syntax #:whole-body-readers? #t #:language-info '#(calc/lang/lang-info get-info #f) (require calc/parser))каковой модуль мы сейчас и создадим (
calc/language.rkt):#lang racket (provide ; Системные вещи, на которых мы не будем заострять внимание. ; Достаточно знать, что #%module-begin и #%datum из racket ; годятся и для calc, поэтому мы переэкспортируем их без изменений #%module-begin #%datum ; Макросы для выполнения операций языка calc assign plus minus divide multiply negate value-of print) ; Окружение = хеш-таблица со значениями переменных (define current-env (make-hash)) ; Присваивание переменной = запись в хеш-таблицу (define-syntax-rule (assign name value) ; Обратите внимание на апостроф перед name: он делает из имени переменной, ; переданной в макрос, символ. Таким образом, из (assign X 3) получается ; (hash-set! current-env 'X 3), в то время как ; (hash-set! current-env X 3) выдало бы ошибку (hash-set! current-env 'name value)) ; Арифметические операции (define-syntax-rule (plus a b) (+ a b)) (define-syntax-rule (minus a b) (- a b)) (define-syntax-rule (divide a b) (/ a b)) (define-syntax-rule (multiply a b) (* a b)) (define-syntax-rule (negate a) (- a)) ; Получение значения переменной по имени (define-syntax-rule (value-of name) ; То же самое с апострофом, см. макрос assign (hash-ref current-env 'name)) ; Печать (define-syntax-rule (print value) (printf "~v\n" value))Теперь можно наконец выполнить (Run) наш
test.calc:

На этом этапе можно считать, что у нас есть парсер и компилятор. Всё это занимает 110 строк, не считая пустых строк и комментариев.
Этап 2: необходимые примочки
Если мы сейчас попробуем запустить отладчик (Debug) и поставить брекпоинт в код программы, нас ждёт неудача. Объясняется это просто: парсер в
calc/parser.rkt возвращает не синтаксические объекты, а простые списки, т.е. datum-ы. Они преобразуются в синтаксические объекты позже, автоматически, но дела это в принципе не меняет, т.к. информации о местоположении синтаксических единиц в исходном коде не появляется. Эта информация известна только парсеру. Он её «забывает» везде, кроме функции on-error. И поставить брекпоинт невозможно, т.к. система просто не знает, какой синтаксический объект к какому месту исходного кода относится. Сейчас мы это исправим (calc/parser.rkt):(define-syntax (build-so stx)
(syntax-case stx ()
((_ value start end)
; вытаскиваем из контекста (stx) $i-start-pos и $j-end-pos, где i и j --
; числа, переданные в макрос как start и end; а также source-name
(with-syntax ((start-pos (datum->syntax
stx
(string->symbol
(format "$~a-start-pos"
(syntax->datum #'start)))))
(end-pos (datum->syntax
stx
(string->symbol
(format "$~a-end-pos"
(syntax->datum #'end)))))
(source (datum->syntax
stx
'source-name)))
(syntax
(datum->syntax
#f
value
; конструируем уже знакомую по on-error пятёрку значений
(list source
(position-line start-pos)
(position-col start-pos)
(position-offset start-pos)
(- (position-offset end-pos)
(position-offset start-pos)))))))))
(define (calc-parser source-name)
(parser
(src-pos)
(start start)
(end EOF)
(tokens value-tokens op-tokens)
(error (on-error source-name))
(grammar
(start
; Числа 1 и 1, переданные в макрос build-so, раскрываются соответственно в
; $1-start-pos и $1-end-pos, каковые переменные доступны благодаря указанию
; (src-pos) выше и содержат начальную и конечную позиции первого нетерминала
; в списке (в данном случае он всего один и есть).
((statements) (build-so $1 1 1)))
(statements
(() '())
((statement statements) (list* $1 $2)))
(statement
((assignment) $1)
((printing) $1))
(constant
((NUMBER) $1))
(expression
((term) $1)
; Числа 1 и 3 раскрываются макросом build-so в $1-start-pos и $3-end-pos
; соответственно, т.е. от начала первого нетерминала до конца третьего.
((expression PLUS term) (build-so (list 'plus $1 $3) 1 3))
((expression MINUS term) (build-so (list 'minus $1 $3) 1 3)))
(term
((factor) $1)
((term MULTIPLY factor) (build-so (list 'multiply $1 $3) 1 3))
((term DIVIDE factor) (build-so (list 'divide $1 $3) 1 3)))
(factor
((primary-expression) $1)
((MINUS primary-expression) (build-so (list 'negate $2) 1 2))
((PLUS primary-expression) $2))
(primary-expression
((constant) $1)
((IDENTIFIER) (build-so (list 'value-of $1) 1 1))
((LEFT-PAREN expression RIGHT-PAREN) (build-so $2 1 3)))
(assignment
((IDENTIFIER ASSIGN expression) (build-so (list 'assign $1 $3) 1 3)))
(printing
((PRINT expression) (build-so (list 'print $2) 1 2))))))И о чудо, теперь работает отладчик, можно ставить брекпоинты, ходить по шагам, даже стек вызовов имеется:
Racket позволяет отладчику заходить в реализацию вашего языка в лисповых функциях, если в момент отладки модули с этими функциями открыты. Но нашего
calc/language.rkt это не касается, поскольку ни одной функции у нас нет — мы обошлись макросами. То есть ближайший уровень, в который может попасть отладчик после кода на calc — это реализация hash-set, + и прочих примитивных вызовов. На такой уровень нам нет необходимости опускаться.Обратим теперь внимание на то, что для языка calc не работает REPL! Об этом честно собщается после выполнения программы (Run) чёрным текстом на жёлтом фоне. REPL не работает потому, что в реализации (
calc/language.rkt) не определён макрос #%top-interaction, который собственно и должен раскрывать полученные в REPL синтаксические объекты. Стандартный макрос из Racket не годится, так что мы напишем свой, очень простой:#lang racket
(provide
#%module-begin #%datum
; Переопределять #%top-interaction внутри модуля нельзя, поэтому мы
; сделаем макрос top-interaction и переименуем его при экспорте.
(rename-out (top-interaction #%top-interaction))
assign plus minus divide multiply negate value-of print)
; Макрос действительно такой -- с троеточиями. Это часть синтаксиса.
(define-syntax-rule (top-interaction body ...)
(begin body ...))Но этого недостаточно. Проблема в том, что декларации #:read и #:read-syntax в calc/reader.rkt по какой-то причине не распространяются на REPL. REPL в DrRacket принадлежит самой DrRacket и подлежит настройке отдельно, по строго определённым правилам. Нужно добавить декларацию #:language-info в calc/reader.rkt:(module reader syntax/module-reader #:language 'calc/language #:read calc-read #:read-syntax calc-read-syntax #:whole-body-readers? #t #:language-info '#(calc/lang/lang-info get-info #f) (require calc/parser))Затем нужно создать модуль
calc/lang/lang-info.rkt такого содержания:#lang racket/base
(provide get-info)
(define (get-info data)
(lambda (key default)
(case key
((configure-runtime)
'(#(calc/lang/configure-runtime configure #f)))
(else
default))))
Наконец, нужно создать модуль calc/lang/configure-runtime.rkt, содержащий функцию конфигурации рантайма:#lang racket/base (require calc/parser) (provide configure) (define (configure data) ; Конфигурация заключается в установке параметра current-read-interaction ; (Параметры в Racket -- что-то вроде динамических переменных в Common Lisp.) ; Мы меняем этот параметр на нашу функцию, которая вызывает наш парсер. (current-read-interaction even-read)) (define (even-read source-name input-port) (begin0 (parse-calc-port input-port source-name) ; Почему-то нужно делать так, чтобы последующий вызов ; current-read-interaction вернул EOF. С этой целью производится ; нижеследующий трюк с заменой параметра на odd-read. (current-read-interaction odd-read))) ; Вторая часть трюка заключается в замене параметра обратно на even-read. ; Среди разработчиков нет согласия по поводу того, правильно ли так делать; ; оставим этот вопрос на их совести, в любом случае все имеющиеся примеры ; работают именно так. (define (odd-read src ip) (current-read-interaction even-read) eof)И вот, у нас работает REPL:

Благодаря умной работе механизма модулей, два и более открытых одновременно окна с программами на calc не конфликтуют и не засоряют окружение друг друга:

Самое время заметить, что ошибки с необъявленными переменными возникают на этапе выполнения программы, тогда как во всех нормальных средах они должны отлавливаться на этапе компиляции. Полноценный компилятор мы писать не будем, ограничимся проверкой того, что все используемые переменные встретились перед использованием в левой части. Файл
calc/compiler.rkt:#lang racket
(provide compile-program
compile-statement)
; Хеш-таблица имён переменных
; (не путать с current-env в language.rkt, это разные этапы)
(define variables (make-hash))
(define (compile-program p)
; проверить все подвыражения (syntax-e раскрывает синтаксический
; объект-список в список синтаксических объектов)
(for-each check-syntax (syntax-e p))
; вернуть исходную синтаксическую конструкцию как результат
; (приличный компилятор вернул бы новую, оптимизированную конструкцию)
p)
(define (compile-statement s)
(check-syntax s)
s)
(define (check-syntax s)
; Что за объект? Преобразуем в данные и посмотрим.
(match (syntax->datum s)
; Команда присваивания
((list 'assign a b)
; Сначала проверим правую часть, чтобы поймать ошибки вида X = X
(check-syntax (third (syntax-e s)))
; Теперь занесём левую часть в словарь
(hash-set! variables a a))
; Доступ к переменной
((list 'value-of a)
; Есть ли она в словаре?
(unless (hash-has-key? variables a)
; Если нет -- ошибка со ссылкой на соответствующий синтаксический объект
(raise-syntax-error
#f "access to unassigned variable" (second (syntax-e s)))))
; Все прочие команды
((list x ...)
; проверяются рекурсивно
(for-each check-syntax (syntax-e s)))
; Константы не подлежат проверке
(_ #f)))
Попросим парсер вызывать "компилятор" перед возвращением результата (calc/parser.lisp):(require parser-tools/yacc
syntax/readerr
calc/lexer
calc/compiler)
(define (calc-read-syntax source-name input-port)
(compile-program
(parse-calc-port input-port source-name)))
Насладимся результатом:
Попросим REPL делать то же самое (
calc/lang/configure-runtime.rkt):(require calc/parser
calc/compiler)
(define (even-read source-name input-port)
(begin0
(compile-statement (parse-calc-port input-port source-name))
(current-read-interaction odd-read)))
Насладимся результатом и здесь:
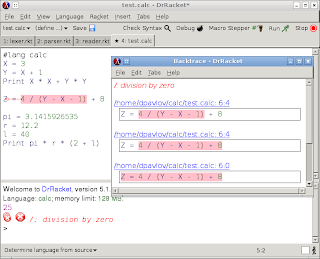
Отметим, что ошибки времени выполнения всё же случаются, и снабжены бектрейсом:

На данный момент у нас есть всё необходимое, а написали мы всего 208 строк кода.
Этап 3: элементы роскоши
Такая беда: REPL не позволяет переводить строку. Нажатие Enter ведёт к немедленному отправлению строки на синтаксический анализ. Мы собирались дописать команду на следующей строке, но REPL безжалостен.

calc/lang/lang-info.rkt:(define (get-info data)
(lambda (key default)
(case key
((configure-runtime)
'(#(calc/lang/configure-runtime configure #f)))
((drracket:submit-predicate)
(dynamic-require 'calc/tool/submit 'repl-submit?))
(else
default))))
и создаём модуль calc/tool/submit.rkt с функцией repl-submit?, которая возвращает #t, если перевод строки завершающий, и #f, если промежуточный. Определить это не так просто, учитывая, что пользователь может вводить в REPL всё, что ему заблагорассудится. Будем считать, что строка готова к синтаксическому анализу, если она не пустая, не завершается оператором (+, -, /, *, =, print) и если скобки в ней сбалансированы. Весьма уместно использовать уже готовый лексический анализатор для выполнения этой задачи:#lang racket
(require calc/lexer
parser-tools/lex)
(provide repl-submit?)
(define (repl-submit? ip has-white-space?)
(let loop ((blank? #t) ; строка пустая?
(pending-op? #f) ; строка завершается оператором?
(paren-count 0)) ; баланс скобок
; Все ошибки лексического анализатора мы обязаны пропускать
(with-handlers ((exn:fail:read?
(lambda (e)
#t)))
(let ((token (position-token-token (calc-lexer ip))))
(case token
((EOF)
(and (zero? paren-count)
(not blank?)
(not pending-op?)))
((PLUS MINUS MULTIPLY DIVIDE ASSIGN PRINT)
(loop #f #t paren-count))
((LEFT-PAREN)
(loop #f #f (+ paren-count 1)))
((RIGHT-PAREN)
(loop #f #f (- paren-count 1)))
(else
(loop #f #f paren-count)))))))
Вроде работает:
Почти всё. Осталось только добавить подсветку синтаксиса. Ну и, например, комментарии, чтобы было что подсвечивать. Пусть комментарии будут в стиле bash — от символа «#» до конца строки. Обновляем
calc/lexer.rkt, попутно экспортируя из него некоторые вещи, которые скоро понадобятся:(provide value-tokens op-tokens
position-line position-col position-offset
calc-lexer
lex:comment lex:identifier lex:number lex-ci)
(define-lex-abbrevs
(lex:letter (:or (:/ #\a #\z) (:/ #\A #\Z)))
(lex:digit (:/ #\0 #\9))
(lex:comment (:: "#" (:* (:: (char-complement #\newline))) (:? #\newline)))
(lex:whitespace (:or #\newline #\return #\tab #\space #\vtab))
(lex:identifier (:: lex:letter (:* (:or lex:letter lex:digit))))
(lex:number (:: (:? #\-) (:+ lex:digit) (:? (:: #\. (:* lex:digit))))))
(define calc-lexer
(lexer-src-pos
((:+ lex:whitespace) (return-without-pos (calc-lexer input-port)))
; комментарии пропускаем так же, как и пробелы
((:+ lex:comment) (return-without-pos (calc-lexer input-port)))
("=" (token-ASSIGN))
("+" (token-PLUS))
("-" (token-MINUS))
("*" (token-MULTIPLY))
("/" (token-DIVIDE))
("(" (token-LEFT-PAREN))
(")" (token-RIGHT-PAREN))
((lex-ci "print") (token-PRINT))
(lex:identifier (token-IDENTIFIER (string->symbol lexeme)))
(lex:number (token-NUMBER (string->number lexeme)))
((eof) 'EOF)))
Информация о подсветке синтаксиса задаётся определённым образом в директиве
#:info файла calc/lang/reader.rkt:(module reader syntax/module-reader
#:language 'calc/language
#:read calc-read
#:read-syntax calc-read-syntax
#:whole-body-readers? #t
#:language-info '#(calc/lang/lang-info get-info #f)
#:info (lambda (key defval default)
(case key
((color-lexer)
(dynamic-require 'calc/tool/syntax-color 'get-syntax-token))
(else (default key defval))))
(require calc/parser))
Собственно подсветку осуществляет отдельный модуль calc/tool/syntax-color.rkt. В нём находится, по сути, ещё один лексический анализатор, но такой, который выдаёт не токены, а особые «пятёрки» значений: лексема, её тип (комментарий/константа/ключевое слово/символ/etc), «скобочность», а также начало и конец лексемы в исходном файле:#lang racket
(require parser-tools/lex
(prefix-in : parser-tools/lex-sre)
calc/lexer)
(provide get-syntax-token)
(define (syn-val lexeme type paren start end)
(values lexeme type paren (position-offset start) (position-offset end)))
(define get-syntax-token
(lexer
((:+ whitespace)
(syn-val lexeme 'whitespace #f start-pos end-pos))
(lex:comment
(syn-val lexeme 'comment #f start-pos end-pos))
(lex:number
(syn-val lexeme 'constant #f start-pos end-pos))
; "Print" у нас будет единственным ключевым словом
((lex-ci "print")
(syn-val lexeme 'keyword #f start-pos end-pos))
; Имена переменных у нас будут идентфикаторами
(lex:identifier
(syn-val lexeme 'symbol #f start-pos end-pos))
; Арифметические операции и "=" будут считаться за скобки
; (Операций кроме скобок Racket, похоже, не знает)
((:or #\+ #\- #\/ #\* #\=)
(syn-val lexeme 'parenthesis #f start-pos end-pos))
; Сами скобки тоже считаются за скобки, и вдобавок к тому обладают свойством
; "скобочности", чтобы редактор Racket подсвечивал открывающие и закрывающие,
; опять же, скобки.
(#\( (syn-val lexeme 'parenthesis '|(| start-pos end-pos))
(#\) (syn-val lexeme 'parenthesis '|)| start-pos end-pos))
((eof) (syn-val lexeme 'eof #f start-pos end-pos))
(any-char (syn-val lexeme 'error #f start-pos end-pos))))
Внимание: чтобы подсветка синтаксиса заработала, надо перезапустить Racket! Если вдуматься, это значит, что при выполнении всех предыдущих операций Racket не надо было перезапускать! И даже test.calc можно было не закрывать. При том, что мы там «резали по живому» во многих местах. Racket истинно динамическая платформа. Вот что получится после перезапуска:

Подсветка синтаксиса в действии. В REPL, правда, она не работает (то есть работает, но не наша, а стандартная), но не будем придираться к мелочам. Racket — прекрасная вещь. Всё вышеописанное мы сделали, написав 268 строк кода. То, что получилось, можно скачать здесь. Вообще-то можно ещё сделать так, чтобы язык calc включался без
#lang calc, и ещё можно научить DrRacket смотреть переменные в отладчике, и ещё можно собрать DrRacket, кастомизированный под calc и готовый к распространению, но обо всём этом как-нибудь в другой раз.вторник, 27 сентября 2011 г.
Как создавать DSL
Необходимость создания предметно-ориентированных языков (domain-specific languages, DSL) может быть продиктована разными причинами. Например, появлением новой технологической ниши, как было с HTML и SQL. Или крайней неуклюжестью давно занявших свои ниши языков общего назначения... не будем их называть. Ещё бывают причины чисто исторические. Неважно. Пусть вам пришла в голову идея сделать DSL. Сочинили вы язык, описали грамматику, продумали семантику, а дальше что? Как получить транслятор, отладчик, где взять удобную среду для написания кода на этом DSL? Не самому же всё делать с нуля. Вот об этом и речь.
Прежде всего надо определиться: DSL или EDSL? Второй вариант, который расшифровывается как «встроенный предметно-ориентированный язык» (embedded DSL, или internal DSL), сделает вашу жизнь значительно легче. Вы выбираете язык общего назначения, для которого все средства разработки уже сделаны до вас, и создаёте свой язык как надстройку над первым, оставаясь в рамках его грамматики. Фактически, вы делаете библиотеку. Само собой, если изначальный язык (хост-язык) недостаточно гибок в плане грамматических конструкций, то и от DSL особенного удобства ждать не приходится. Тем не менее, можно на Ruby, C#, Scala создавать вполне удобные EDSL. Даже на C++ с шаблонами можно создавать совершенно потрясающие вещи.
Вообще говоря, если вы выбрали EDSL — т.е. готовы жертвовать грамматикой языка ради готовых средств разработки — то почему бы не жертвовать до конца. Откажитесь от грамматики и задавайте программу сразу как экземпляр метамодели (что принято называть абстрактным синтаксическим деревом, хотя оно не абстрактное, да и к синтаксису отношения не имеет). Возьмите платформу, которая заточена под работу с такими программами. Речь, конечно, о семействе лиспов (Common Lisp, Scheme, Clojure). Никакого синтаксиса, кроме простейших S-выражений. Динамическая типизация. Система компилируемых макросов. Культура инкрементальной разработки. Лиспам нет равных в быстроте и удобстве создания EDSL. В знаменитой книге SICP мини-языки в рамках Scheme создаются практически под каждую задачу, и даже без использования макросов.
Мы подошли к месту, когда нельзя не упомянуть JetBrains MPS. Это весьма оригинальная вещь. В компании, где пишут среды разработки для мейнстримных языков программирования, зародилась идея создания IDE для создания IDE для создания DSL. По качеству аналогичных мейнстримным. С автодополнениями, рефакторингами, удобными отладчиками. Сами посудите, какой тут может быть лисп. В лиспе отсутствует культура автодополнений и рефакторинга, не развит статический анализ кода, зато повсюду кошмарные скобки. Лисп не годился. Пара вещей, однако, была заимствована из него: отказ от синтаксиса и макросы. Первое было даже не просто заимствовано, а доведено до абсолюта. В MPS нет ни парсера S-выражений, ни какого-либо другого парсера. Потому что в MPS нет кода. Редактор MPS работает не с кодом, а непосредственно с экземпляром метамодели. В целях облегчения перехода разработчиков на данную технологию редактор напоминает текстовый, декорируя и отображая дерево так, что оно выглядит как код, но им не является. Инструментов для импорта кода MPS не предоставляет (за исключением кода на Java). Что касается макросов для кодогенерации в MPS, то они там завязаны на строгую систему типов, что позволяет автоматически делать статическую проверку типов для создаваемого DSL.
Те, кто говорят, что MPS это переизобретение Лиспа, неправы. Скорее, MPS — это скачок к визуальному метапрограммированию будущего. Что не означает, однако, что этот скачок удачный. Время покажет. Возможно, молодое поколение будет очаровано визуальной средой MPS и автодополнениями. С другой стороны, им может помешать изолированность MPS от мира текстовых программ, т.к. сейчас практически все языки текстовые. Их также может отпугнуть тотальная бюрократизация всего процесса программирования (что неудивительно при хост-платформе Java). В общем, выбор делать им, а мы идём дальше, рассматривая тот случай, когда вам нужен именно текстовый DSL, со своей уникальной грамматикой.
Итак, вы желаете реализовать настоящий DSL. С транслятором проблем не будет — связка lex+yacc, портированная, кажется, на все платформы в мире, уже лет 40 выполняет задачу автоматического построения парсеров. Для грамматик, которым не хватает yacc, есть другие инструменты. Но отладчик и IDE придётся писать самостоятельно. Если только не... найти хост-язык с настраиваемой грамматикой и взять существующую IDE для него. Если она не сломается от введения новой грамматики. Фактически, получится EDSL, но без ограничений на синтаксис, которые накладывались бы нерасширяемым хост-языком. Этот подход называется «extensible programming»; он был довольно популярен в1960-х, потом заглох, и ожил только в XXI веке. Поэтому живых языков с настраиваемой грамматикой не очень много.
Как видите, в принципе есть инструменты на любой вкус и под любые требования. В наше время создавать DSL стало не только полезно, но и приятно.
Автор признателен LOR-у за подсказки и Ф.А.Новикову за вычитывание черновика.
Прежде всего надо определиться: DSL или EDSL? Второй вариант, который расшифровывается как «встроенный предметно-ориентированный язык» (embedded DSL, или internal DSL), сделает вашу жизнь значительно легче. Вы выбираете язык общего назначения, для которого все средства разработки уже сделаны до вас, и создаёте свой язык как надстройку над первым, оставаясь в рамках его грамматики. Фактически, вы делаете библиотеку. Само собой, если изначальный язык (хост-язык) недостаточно гибок в плане грамматических конструкций, то и от DSL особенного удобства ждать не приходится. Тем не менее, можно на Ruby, C#, Scala создавать вполне удобные EDSL. Даже на C++ с шаблонами можно создавать совершенно потрясающие вещи.
Вообще говоря, если вы выбрали EDSL — т.е. готовы жертвовать грамматикой языка ради готовых средств разработки — то почему бы не жертвовать до конца. Откажитесь от грамматики и задавайте программу сразу как экземпляр метамодели (что принято называть абстрактным синтаксическим деревом, хотя оно не абстрактное, да и к синтаксису отношения не имеет). Возьмите платформу, которая заточена под работу с такими программами. Речь, конечно, о семействе лиспов (Common Lisp, Scheme, Clojure). Никакого синтаксиса, кроме простейших S-выражений. Динамическая типизация. Система компилируемых макросов. Культура инкрементальной разработки. Лиспам нет равных в быстроте и удобстве создания EDSL. В знаменитой книге SICP мини-языки в рамках Scheme создаются практически под каждую задачу, и даже без использования макросов.
Мы подошли к месту, когда нельзя не упомянуть JetBrains MPS. Это весьма оригинальная вещь. В компании, где пишут среды разработки для мейнстримных языков программирования, зародилась идея создания IDE для создания IDE для создания DSL. По качеству аналогичных мейнстримным. С автодополнениями, рефакторингами, удобными отладчиками. Сами посудите, какой тут может быть лисп. В лиспе отсутствует культура автодополнений и рефакторинга, не развит статический анализ кода, зато повсюду кошмарные скобки. Лисп не годился. Пара вещей, однако, была заимствована из него: отказ от синтаксиса и макросы. Первое было даже не просто заимствовано, а доведено до абсолюта. В MPS нет ни парсера S-выражений, ни какого-либо другого парсера. Потому что в MPS нет кода. Редактор MPS работает не с кодом, а непосредственно с экземпляром метамодели. В целях облегчения перехода разработчиков на данную технологию редактор напоминает текстовый, декорируя и отображая дерево так, что оно выглядит как код, но им не является. Инструментов для импорта кода MPS не предоставляет (за исключением кода на Java). Что касается макросов для кодогенерации в MPS, то они там завязаны на строгую систему типов, что позволяет автоматически делать статическую проверку типов для создаваемого DSL.
Те, кто говорят, что MPS это переизобретение Лиспа, неправы. Скорее, MPS — это скачок к визуальному метапрограммированию будущего. Что не означает, однако, что этот скачок удачный. Время покажет. Возможно, молодое поколение будет очаровано визуальной средой MPS и автодополнениями. С другой стороны, им может помешать изолированность MPS от мира текстовых программ, т.к. сейчас практически все языки текстовые. Их также может отпугнуть тотальная бюрократизация всего процесса программирования (что неудивительно при хост-платформе Java). В общем, выбор делать им, а мы идём дальше, рассматривая тот случай, когда вам нужен именно текстовый DSL, со своей уникальной грамматикой.
Итак, вы желаете реализовать настоящий DSL. С транслятором проблем не будет — связка lex+yacc, портированная, кажется, на все платформы в мире, уже лет 40 выполняет задачу автоматического построения парсеров. Для грамматик, которым не хватает yacc, есть другие инструменты. Но отладчик и IDE придётся писать самостоятельно. Если только не... найти хост-язык с настраиваемой грамматикой и взять существующую IDE для него. Если она не сломается от введения новой грамматики. Фактически, получится EDSL, но без ограничений на синтаксис, которые накладывались бы нерасширяемым хост-языком. Этот подход называется «extensible programming»; он был довольно популярен в
- Forth — старейший из таких языков. Отличается тем, что «своей» грамматики практически не имеет. Таков же его преемник Factor. Программирование на Forth, однако, может оказаться не таким простым.
- Common Lisp отметился и здесь. Помимо defmacro, которые используются для создания «скобочных» EDSL, о которых было сказано выше, в CL есть т.н. reader macros, которые позволяют изменить поведение reader-а, т.е. расширить синтаксис. Чтобы не конфликтовать со стандартным синтаксисом CL, reader macros обычно начинаются с «#», хотя могут начинаться и с любого другого символа. Например, #c(0, 1) — запись мнимой единицы одним из стандартных макросов CL. Есть примеры более развесистых макросов: запуск shell-команд прямо из CL, вызов
C-функций , синтаксис для хеш-таблиц, расширенный синтаксис строк, и даже встраивание XML непосредственно в лисповый код. Однако, если, синтаксис вашего DSL конфликтует с синтаксисом S-выражений, то дело может оказаться труднее. В теории, ничто не мешает изменить стандартный reader на собственный, но как это будет на практике, и как на это отреагирует ваша IDE (например SLIME), пока не ясно. Похоже, никто серьёзно не занимался этим вопросом в CL. - Racket — бывшая PLT Scheme — совсем другое дело. Платформа «из коробки» поддерживает концепцию переключения между разными языками, и позволяет создавать новые языки, используя при этом генератор парсеров в стиле yacc. Есть примеры «не-скобочных» языков, созданных на Racket, по мотивам Prolog, Brainfuck и Algol 60. Среда (DrRacket) и её отладчик работают с этими языками. Более того, DrRacket написан на Racket же, что открывает возможности для модификации среды под язык и распространения её в качестве IDE для вашего DSL. Словом, Racket — очень перспективная платформа для создания DSL, и поддерживается в прекрасном состоянии.
- Nemerle — статически типизированный язык для .NET с макросами и расширяемым синтаксисом. Возможности расширения, однако, ограничены. Есть проект Nemerle 2, в котором ограничения будут сняты, и который обещает стать чем-то вроде MPS для .NET (но без отказа от грамматик). Пока только обещает, впрочем.
- Bigloo — ещё одна реализация Scheme, с упором на быстродействие. Так же, как и Racket, обладает средствами генерации парсеров, и поддерживает макросы, однако не имеет такого удобного механизма переключения языков и создания новых. Кроме того, не факт, что отладчик Bigloo и его IDE (основанное на Emacs) будут нормально работать с новыми языками, ибо, как и с CL, вряд ли кто-то специально занимался этим вопросом, а само собой ничего не делается.
- Helvetia — уникальная в своём роде разработка на базе языка Smalltalk, в которой используется то обстоятельство, что вся среда Smalltalk (включая парсер) поддаётся изменению в рантайме. Helvetia — инструмент для произвольного расширения синтаксиса Smalltalk. С сохранением отладки. И даже с подсветкой и автодополнением! Что делает MPS не совсем уникальной средой. Примеры включают SQL, Brainfuck и что-то похожее на CSS. Единственная неприятность — автор Helvetia защитил по ней PhD, ушёл работать в Google и забросил своё творение. Helvetia работает только на Pharo Smalltalk версии 1.1, и не портирована ни на современную версию Pharo (1.3), ни на Squeak. Однако автор иногда что-то делает, всё-таки. Жаль, что кроме него, никто в разработке Helvetia не участвует. Кстати, автор в 2009 г. выбрал в качестве хост-языка Smalltalk (а не Lisp) по причине «однородности» языка и среды. Среды разработки Smalltalk написаны на Smalltalk, а про Scheme или CL такого сказать было нельзя. DrRacket в то время был наполовину написан на C++, и его переписали на чистом Racket только в феврале 2011.
Как видите, в принципе есть инструменты на любой вкус и под любые требования. В наше время создавать DSL стало не только полезно, но и приятно.
Автор признателен LOR-у за подсказки и Ф.А.Новикову за вычитывание черновика.
вторник, 20 сентября 2011 г.
Горькая правда о Питоне и его Global Interpreter Lock (цитата)
GIL не уберут никогда. Или, по крайней мере, в ближайший десяток лет. Сейчас никаких работ на эту тему не ведется. Если некий гений предъявит работающую реализацию без GIL, ничего не ломающую и работающую не медленней, чем существующая версия — предложению будет открыт зеленый свет. Пока же «убрать GIL» проходит по части благих, но невыполнимых пожеланий.
В Java и C# никакого GIL нет. Потому что у них иначе устроен garbage collector. Если хотите, он более прогрессивный. Переделать GC Питона, не сломав обратной совместимости со всеми существующими библиотеками, использующими Python C API — невозможно. Сообщество и так уже который год лихорадит в связи с переходом на Python 3.x. Разработчики не желают выкатывать второе революционное изменение, не разобравшись с первым. Ждите Python 4.x (которого нет даже в планах) — до тех пор ничего не поменяется.
суббота, 10 сентября 2011 г.
Искал работу
Для кого-то поиск работы — это унылое листание унылых вакансий, слащавые письма от слащавых рекрутеров, пробивание стен HR-отделов и т.п. Можно, конечно, и так. Но по факту — существуют хорошие работы, но не существует рынка хороших работ. Хорошие работы появляются тогда, когда кто-то хочет сделать что-то новое и крутое, вне устоявшегося положения вещей (нет, не веб-стартап, вы меня не так поняли). Из чего следует, что вакансии нерелевантны, рекрутеры не в теме, а HR вообще по жизни не в теме.
Общаться надо с теми самыми, которые (см. выше).
И вы никогда не пожалеете об этом, вне зависимости от своих карьерных планов.
Вам рассказывают об актуальных проблемах, преграждающих путь в светлое технологическое будущее. Вам показывают невиданные девайсы. Вы общаетесь с корифеями, которые своей волей определяют направления развития науки и техники. Это выставка-конференция-презентация, на которой вы — единственный зритель и слушатель.
Программисты сейчас нужны почти везде, так что для данной профессии «правильный» поиск работы немало расширяет горизонты. В одном Питере, не говоря уже о других городах и странах, делают:
Общаться надо с теми самыми, которые (см. выше).
И вы никогда не пожалеете об этом, вне зависимости от своих карьерных планов.
Вам рассказывают об актуальных проблемах, преграждающих путь в светлое технологическое будущее. Вам показывают невиданные девайсы. Вы общаетесь с корифеями, которые своей волей определяют направления развития науки и техники. Это выставка-конференция-презентация, на которой вы — единственный зритель и слушатель.
Программисты сейчас нужны почти везде, так что для данной профессии «правильный» поиск работы немало расширяет горизонты. В одном Питере, не говоря уже о других городах и странах, делают:
- Военные симуляторы; составление трёхмерных карт местности по снимкам с беспилотников; трёхмерную карту города для городских служб
- Программные комплексы для авиадиспетчеров; тренажёры для них же
- Программы для симуляции плазмы; анализ гамма-всплесков
- Передовые средства разработки
- Программу для расчёта оптимальной конструкции крыла самолёта
- Обработку и синтез речи
- Расчёт движения небесных тел; обработку огромных потоков данных с радиотелескопов
- Софт для фармацевтических компаний и институтов (старое место работы)
пятница, 24 июня 2011 г.
О краткости языка (On the Conciseness of Language)
Английский язык более ёмкий, чем русский. Каждый русскоговорящий гражданин когда-то узнаёт это в первый раз. Лично я об этом прочёл в 8-м классе в детективе одной современной отечественной писательницы детективов (кажется, в нём же я узнал об асимметричной схеме шифрования с открытым ключом, которая подавалась авторшей как личное изобретение одного из преследуемых милицией злодеев). Впоследствии я не испытывал недостатка в подкрепляющих примерах. Многие английские слова короче своих аналогов на русском, а ещё короче комбинации «прилагательное+существительное». Чего стоят одни только «exit polls» — тележурналисты бросили пытаться их переводить и так и говорят, по-английски. Английский язык гибче и выразительнее, это был очевидный факт.
Шли годы.
Я узнавал больше о языке, и во мне росло сомнение.
Сейчас я убеждён в том, что мнение о ёмкости английского языка по сравнению с русским происходит от недостаточного знания английского. Или русского. Языки по ёмкости не различаются.
Тексты, переведённые любителями с английского на русский, тоже зачастую длиннее оригиналов. И большинство их выглядит настолько нелепо, что сразу видно, что это перевод. Читаешь и видишь: по-русски так никогда не написали бы.
Короче, плохие переводы = плохая репутация, не более того. Чтобы составить мнение о языке, надо смотреть на хорошие переводы хороших текстов. Например: краткая история Талибана (на русском, на английском). Оригинал и перевод чуть-чуть отличаются в деталях, которые делают каждый из двух текстов доступнее для носителей соответствующего языка, но это закон стиля, иначе было бы не по-настоящему. К тому же, детали там уравновешивают друг друга, так что можно считать тексты равными по количеству информации.
Так вот: русский вариант содержит 15181 букв и цифр (пробелы и знаки препинания не в счёт), а английский — 16239. Разница в пользу русского, но в пределах статистической погрешности.
Возьмём фрагмент поменьше, из повести Пелевина «Зомбификация», глава «Бульдозер»:
Но это просто примеры. Может быть, есть какое-то теоретическое обоснование ёмкости английского языка перед русским? Мне о таком неизвестно. В английском нет падежей — зато есть частичка «to» и артикли, которые в русском очень редко являются обязательными, а в английском — очень часто. В английском проще словообразование — но при этом жёсткий порядок слов в предложении. В английском нет сложных окончаний — но есть довольно запутанная система «времён». Английский язык аналитический, а русский синтетический — но это ничего не говорит о ёмкости.
При желании русский интерфейс можно сделать таким же кратким (например, Cut/Copy/Paste переводить как Режь/Множь/Клей). Это вопрос традиции, а не языка. Сложилась традиция писать длинно, вот и всё.
Шли годы.
Я узнавал больше о языке, и во мне росло сомнение.
Сейчас я убеждён в том, что мнение о ёмкости английского языка по сравнению с русским происходит от недостаточного знания английского. Или русского. Языки по ёмкости не различаются.
Тексты
Часто так бывает: пишет человек письмо или статью на русском, а потом самостоятельно переводит на английский, и второй вариант получается компактнее. Потом оказывается, что у него «is» вместо «is being», «was» вместо «has been», «I will» вместо «I am going to», «for» вместо «in order to», «it’s» вместо «it is» (вариант с апострофом, вообще-то, является разговорным, и допускается только в прямой речи или сильно неформальном письме), артикли забыты в половине мест, и вообще такой текст носитель языка прочтёт лишь изрядно поморщившись, потому что фразы построены неверно. Или ещё бывает наоборот, над английским текстом автор постарается, дабы не уронить лицо, и напишет ясно и лаконично; а в русском варианте оставит разные там «исходя из вышеизложенного, совершенно очевидно, что».Тексты, переведённые любителями с английского на русский, тоже зачастую длиннее оригиналов. И большинство их выглядит настолько нелепо, что сразу видно, что это перевод. Читаешь и видишь: по-русски так никогда не написали бы.
Короче, плохие переводы = плохая репутация, не более того. Чтобы составить мнение о языке, надо смотреть на хорошие переводы хороших текстов. Например: краткая история Талибана (на русском, на английском). Оригинал и перевод чуть-чуть отличаются в деталях, которые делают каждый из двух текстов доступнее для носителей соответствующего языка, но это закон стиля, иначе было бы не по-настоящему. К тому же, детали там уравновешивают друг друга, так что можно считать тексты равными по количеству информации.
Так вот: русский вариант содержит 15181 букв и цифр (пробелы и знаки препинания не в счёт), а английский — 16239. Разница в пользу русского, но в пределах статистической погрешности.
Возьмём фрагмент поменьше, из повести Пелевина «Зомбификация», глава «Бульдозер»:
Представим себе небольшое село, стоящее на холме — некоторые дома уже очень стары, другие, наоборот, построены по самым последним проектам, а большинство — нечто среднее между первым и вторым. Бок о бок стоят полузаброшенная церковь и недостроенный клуб. В одних окнах мигает керосиновая лампа, в других горит электричество, где-то чуть слышно играет балалайка, которую перекрывает радиомузыка со столба. Словом, обычная жизнь, остатки нового и старого, переплетенные самым причудливым образом.
Теперь представим себе бульдозериста, который, начитавшись каких-то брошюр, решил смести всю эту отсталость и построить новый поселок на совершенно гладком месте. Сырой октябрьской ночью он садится в бульдозер и в несколько приемов срезает всю верхнюю часть холма с деревней и жителями. И вот, когда бульдозер крутится в грязи, разравнивая будущую стройплощадку, происходит нечто совершенно неожиданное: бульдозер вдруг проваливается в подземную пустоту — вокруг оказываются какие-то полусгнившие бревна, человеческие и лошадиные скелеты, черепки и куски ржавчины. Бульдозер оказался в могиле. Ни бульдозерист, ни авторы вдохновивших его брошюр не учли, что когда они сметут все, что по их мнению устарело, обнажится то, что было под этим, то есть нечто куда более древнее.
Психика человека точно так же имеет множество культурных слоев. Если срезать верхний слой психической культуры, объявив его набором предрассудков, заблуждений и классово чуждых точек зрения, обнажится темное бессознательное с остатками существовавших раньше психических образований. Все преемственно, вчерашнее вложено в сегодняшнее, как матрешка в матрешку, и тот, кто попробует снять с настоящего стружку, чтобы затем раскрасить его под будущее, в результате провалится в очень далекое прошлое.Перевод, выполненный вашим покорным слугой, был отредактирован и заверен расовым носителем британского английского. Перевод точный, ничего не упущено и не добавлено.
Let us picture a village standing on a hill, with some houses being very old and some others designed along up-to-date lines, while the majority is somewhere between the two. A semi-abandoned church stands side by side with an unfinished workers’ club. In some windows, kerosene lamps flicker, while in some others, electric light burns. Barely audible, a balalaika plays, drowned by music from a radio on a street pole. In sum, that is a piece of ordinary life, odds and ends of old and new, twisted around each other in a most cranky way.
Now, let us picture a bulldozer driver who, having overdosed on some brochures or other, has taken the decision to slice away all that backwardness and build up a new village from scratch. So in the middle of a raw October night he sits behind the wheel of his bulldozer and, bit by bit, cuts off the entire top of the hill along with the village and its inhabitants. And now, while the bulldozer is spinning in the mud, leveling out the new building site, something very unexpected happens: the bulldozer suddenly falls into a void and finds itself among half-rotten logs, skeletons of men and horses, some shards and rusty smithers. The bulldozer is caught in a grave. Neither the driver nor the authors of those brochures that inspired him had taken into account that as soon as they wipe away everything that is—in their opinion—obsolete, something deep crops out, something much more ancient.
Human psyche—in exactly the same way—has a lot of cultural layers. If one cuts off the upper layer of the culture, declaring it a pile of superstitions, delusions and class-alien points of view, then the darkness of the unconscious crops out together with some preexistent psychic traits. Everything is successive, yesterday nests into today, like one Russian doll inside another, and whoever takes the liberty of planing away the present in order to paint it with colors of the future, will only fall into a very distant past.В оригинале 1469 букв, в переводе 1576. Разница опять в пользу русского и в пределах статистической погрешности.
Но это просто примеры. Может быть, есть какое-то теоретическое обоснование ёмкости английского языка перед русским? Мне о таком неизвестно. В английском нет падежей — зато есть частичка «to» и артикли, которые в русском очень редко являются обязательными, а в английском — очень часто. В английском проще словообразование — но при этом жёсткий порядок слов в предложении. В английском нет сложных окончаний — но есть довольно запутанная система «времён». Английский язык аналитический, а русский синтетический — но это ничего не говорит о ёмкости.
Речь
В английской речи допустимы сокращения, такие как «it’s», «I’ll», «you’d», «can’t». С другой стороны, английская речь должна звучать длинно. Чем длиннее, тем вежливее, это закон. В русском для вежливости полезна интонация, обращение на «вы» и перестановка слов — в английском интонация не играет большой роли, «вы» отсутствует, а перестановки слов редки. Когда на русском говорят «[сделайте ч.-л.], пожалуйста», на английском то же самое должно звучать как «could you please [do smth]». Короткое, но вежливо сказанное «нет» переводится как «I don’t think so». И так далее. Короткие фразы уместны в армии, больнице и т.п. местах, где проволочки ни к чему. Бросаться же короткими фразами в бытовом общении — значит быть невежливым (в частности из-за этого хорошо воспитанных русских за границей считают плохо воспитанными).Софт
Интерфейсы программ на русском всегда длиннее аналогичных им на английском, но при этом они более корректные. Для англоговорящего человека любое меню в любой программе выглядит неграмотным и местами написанным по-хамски. Все слова очень короткие и не вполне отражающие суть (фактически, это просто некие условные знаки), артиклей нет, фразы выглядят как армейские команды.При желании русский интерфейс можно сделать таким же кратким (например, Cut/Copy/Paste переводить как Режь/Множь/Клей). Это вопрос традиции, а не языка. Сложилась традиция писать длинно, вот и всё.
Подписаться на:
Комментарии (Atom)